| 1 |
DENIED
|
ROLE_USER
|
null |
|
Show voter details
|
| 2 |
DENIED
|
moderate
|
Proxies\__CG__\App\Entity\Entry {#1582
+user: Proxies\__CG__\App\Entity\User {#1620 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "How-to-begin-setting-up-a-media-center"
+title: "How to begin setting up a media center?"
+url: null
+body: """
I have 16TB NAS dedicated to storing TV shows. It is just a cabinet with ryzen 2600 and no graphics card. I have installed openmediavault in it to access it via smb to other devices. I am an absolute noob in setting up a server. Please tell me how I should go on about turning it into a media consumption machine.\n
\n
P. S: I usually use VLC on android and MPV on linux to consume the media.
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 40
+favouriteCount: 118
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699372560 {#1617
date: 2023-11-07 16:56:00.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#1626 …}
+votes: Doctrine\ORM\PersistentCollection {#2383 …}
+reports: Doctrine\ORM\PersistentCollection {#1883 …}
+favourites: Doctrine\ORM\PersistentCollection {#1906 …}
+notifications: Doctrine\ORM\PersistentCollection {#1708 …}
+badges: Doctrine\ORM\PersistentCollection {#2391 …}
+children: [
App\Entity\EntryComment {#1709
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1582 …2}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: null
+root: null
+body: """
For sailing the high seas/acquiring more Linux ISOs, get a torrent-client, qbitorent is probably the most popular (and depending on where you are a vpn-subscription), then set it up with the arrs:\n
\n
[wiki.servarr.com](https://wiki.servarr.com/)
"""
+lang: "en"
+isAdult: false
+favouriteCount: 4
+score: 0
+lastActive: DateTime @1699130393 {#1435
date: 2023-11-04 21:39:53.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@agame@lemm.ee"
]
+children: Doctrine\ORM\PersistentCollection {#1572 …}
+nested: Doctrine\ORM\PersistentCollection {#1581 …}
+votes: Doctrine\ORM\PersistentCollection {#1579 …}
+reports: Doctrine\ORM\PersistentCollection {#1577 …}
+favourites: Doctrine\ORM\PersistentCollection {#1573 …}
+notifications: Doctrine\ORM\PersistentCollection {#1650 …}
-id: 90772
-bodyTs: "'/)':40 'arr':36 'client':13 'depend':21 'get':9 'high':4 'iso':8 'linux':7 'popular':19 'probabl':16 'qbitor':14 'sail':2 'seas/acquiring':5 'set':31 'subscript':29 'torrent':12 'torrent-cli':11 'vpn':28 'vpn-subscript':27 'wiki.servarr.com':37,39 'wiki.servarr.com/)':38"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563757"
+editedAt: null
+createdAt: DateTimeImmutable @1699130393 {#1438
date: 2023-11-04 21:39:53.0 +01:00
}
+"title": 90772
}
]
-id: 9762
-titleTs: "'begin':3 'center':8 'media':7 'set':4"
-bodyTs: "'16tb':3 '2600':17 'absolut':39 'access':29 'android':69 'cabinet':14 'card':21 'consum':75 'consumpt':60 'dedic':5 'devic':35 'go':52 'graphic':20 'instal':24 'linux':73 'machin':61 'media':59,77 'mpv':71 'nas':4 'noob':40 'openmediavault':25 'p':62 'pleas':46 'ryzen':16 'server':45 'set':42 'show':9 'smb':32 'store':7 'tell':47 'turn':55 'tv':8 'use':66 'usual':65 'via':31 'vlc':67"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699190737
+visibility: "visible "
+apId: "https://lemm.ee/post/13813898"
+editedAt: null
+createdAt: DateTimeImmutable @1699104337 {#1630
date: 2023-11-04 14:25:37.0 +01:00
}
+__isInitialized__: true
…2
} |
|
Show voter details
|
| 3 |
DENIED
|
edit
|
Proxies\__CG__\App\Entity\Entry {#1582
+user: Proxies\__CG__\App\Entity\User {#1620 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "How-to-begin-setting-up-a-media-center"
+title: "How to begin setting up a media center?"
+url: null
+body: """
I have 16TB NAS dedicated to storing TV shows. It is just a cabinet with ryzen 2600 and no graphics card. I have installed openmediavault in it to access it via smb to other devices. I am an absolute noob in setting up a server. Please tell me how I should go on about turning it into a media consumption machine.\n
\n
P. S: I usually use VLC on android and MPV on linux to consume the media.
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 40
+favouriteCount: 118
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699372560 {#1617
date: 2023-11-07 16:56:00.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#1626 …}
+votes: Doctrine\ORM\PersistentCollection {#2383 …}
+reports: Doctrine\ORM\PersistentCollection {#1883 …}
+favourites: Doctrine\ORM\PersistentCollection {#1906 …}
+notifications: Doctrine\ORM\PersistentCollection {#1708 …}
+badges: Doctrine\ORM\PersistentCollection {#2391 …}
+children: [
App\Entity\EntryComment {#1709
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1582 …2}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: null
+root: null
+body: """
For sailing the high seas/acquiring more Linux ISOs, get a torrent-client, qbitorent is probably the most popular (and depending on where you are a vpn-subscription), then set it up with the arrs:\n
\n
[wiki.servarr.com](https://wiki.servarr.com/)
"""
+lang: "en"
+isAdult: false
+favouriteCount: 4
+score: 0
+lastActive: DateTime @1699130393 {#1435
date: 2023-11-04 21:39:53.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@agame@lemm.ee"
]
+children: Doctrine\ORM\PersistentCollection {#1572 …}
+nested: Doctrine\ORM\PersistentCollection {#1581 …}
+votes: Doctrine\ORM\PersistentCollection {#1579 …}
+reports: Doctrine\ORM\PersistentCollection {#1577 …}
+favourites: Doctrine\ORM\PersistentCollection {#1573 …}
+notifications: Doctrine\ORM\PersistentCollection {#1650 …}
-id: 90772
-bodyTs: "'/)':40 'arr':36 'client':13 'depend':21 'get':9 'high':4 'iso':8 'linux':7 'popular':19 'probabl':16 'qbitor':14 'sail':2 'seas/acquiring':5 'set':31 'subscript':29 'torrent':12 'torrent-cli':11 'vpn':28 'vpn-subscript':27 'wiki.servarr.com':37,39 'wiki.servarr.com/)':38"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563757"
+editedAt: null
+createdAt: DateTimeImmutable @1699130393 {#1438
date: 2023-11-04 21:39:53.0 +01:00
}
+"title": 90772
}
]
-id: 9762
-titleTs: "'begin':3 'center':8 'media':7 'set':4"
-bodyTs: "'16tb':3 '2600':17 'absolut':39 'access':29 'android':69 'cabinet':14 'card':21 'consum':75 'consumpt':60 'dedic':5 'devic':35 'go':52 'graphic':20 'instal':24 'linux':73 'machin':61 'media':59,77 'mpv':71 'nas':4 'noob':40 'openmediavault':25 'p':62 'pleas':46 'ryzen':16 'server':45 'set':42 'show':9 'smb':32 'store':7 'tell':47 'turn':55 'tv':8 'use':66 'usual':65 'via':31 'vlc':67"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699190737
+visibility: "visible "
+apId: "https://lemm.ee/post/13813898"
+editedAt: null
+createdAt: DateTimeImmutable @1699104337 {#1630
date: 2023-11-04 14:25:37.0 +01:00
}
+__isInitialized__: true
…2
} |
|
Show voter details
|
| 4 |
DENIED
|
moderate
|
Proxies\__CG__\App\Entity\Entry {#1582
+user: Proxies\__CG__\App\Entity\User {#1620 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "How-to-begin-setting-up-a-media-center"
+title: "How to begin setting up a media center?"
+url: null
+body: """
I have 16TB NAS dedicated to storing TV shows. It is just a cabinet with ryzen 2600 and no graphics card. I have installed openmediavault in it to access it via smb to other devices. I am an absolute noob in setting up a server. Please tell me how I should go on about turning it into a media consumption machine.\n
\n
P. S: I usually use VLC on android and MPV on linux to consume the media.
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 40
+favouriteCount: 118
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699372560 {#1617
date: 2023-11-07 16:56:00.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#1626 …}
+votes: Doctrine\ORM\PersistentCollection {#2383 …}
+reports: Doctrine\ORM\PersistentCollection {#1883 …}
+favourites: Doctrine\ORM\PersistentCollection {#1906 …}
+notifications: Doctrine\ORM\PersistentCollection {#1708 …}
+badges: Doctrine\ORM\PersistentCollection {#2391 …}
+children: [
App\Entity\EntryComment {#1709
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1582 …2}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: null
+root: null
+body: """
For sailing the high seas/acquiring more Linux ISOs, get a torrent-client, qbitorent is probably the most popular (and depending on where you are a vpn-subscription), then set it up with the arrs:\n
\n
[wiki.servarr.com](https://wiki.servarr.com/)
"""
+lang: "en"
+isAdult: false
+favouriteCount: 4
+score: 0
+lastActive: DateTime @1699130393 {#1435
date: 2023-11-04 21:39:53.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@agame@lemm.ee"
]
+children: Doctrine\ORM\PersistentCollection {#1572 …}
+nested: Doctrine\ORM\PersistentCollection {#1581 …}
+votes: Doctrine\ORM\PersistentCollection {#1579 …}
+reports: Doctrine\ORM\PersistentCollection {#1577 …}
+favourites: Doctrine\ORM\PersistentCollection {#1573 …}
+notifications: Doctrine\ORM\PersistentCollection {#1650 …}
-id: 90772
-bodyTs: "'/)':40 'arr':36 'client':13 'depend':21 'get':9 'high':4 'iso':8 'linux':7 'popular':19 'probabl':16 'qbitor':14 'sail':2 'seas/acquiring':5 'set':31 'subscript':29 'torrent':12 'torrent-cli':11 'vpn':28 'vpn-subscript':27 'wiki.servarr.com':37,39 'wiki.servarr.com/)':38"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563757"
+editedAt: null
+createdAt: DateTimeImmutable @1699130393 {#1438
date: 2023-11-04 21:39:53.0 +01:00
}
+"title": 90772
}
]
-id: 9762
-titleTs: "'begin':3 'center':8 'media':7 'set':4"
-bodyTs: "'16tb':3 '2600':17 'absolut':39 'access':29 'android':69 'cabinet':14 'card':21 'consum':75 'consumpt':60 'dedic':5 'devic':35 'go':52 'graphic':20 'instal':24 'linux':73 'machin':61 'media':59,77 'mpv':71 'nas':4 'noob':40 'openmediavault':25 'p':62 'pleas':46 'ryzen':16 'server':45 'set':42 'show':9 'smb':32 'store':7 'tell':47 'turn':55 'tv':8 'use':66 'usual':65 'via':31 'vlc':67"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699190737
+visibility: "visible "
+apId: "https://lemm.ee/post/13813898"
+editedAt: null
+createdAt: DateTimeImmutable @1699104337 {#1630
date: 2023-11-04 14:25:37.0 +01:00
}
+__isInitialized__: true
…2
} |
|
Show voter details
|
| 5 |
DENIED
|
ROLE_USER
|
null |
|
Show voter details
|
| 6 |
DENIED
|
moderate
|
App\Entity\EntryComment {#1709
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1582
+user: Proxies\__CG__\App\Entity\User {#1620 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "How-to-begin-setting-up-a-media-center"
+title: "How to begin setting up a media center?"
+url: null
+body: """
I have 16TB NAS dedicated to storing TV shows. It is just a cabinet with ryzen 2600 and no graphics card. I have installed openmediavault in it to access it via smb to other devices. I am an absolute noob in setting up a server. Please tell me how I should go on about turning it into a media consumption machine.\n
\n
P. S: I usually use VLC on android and MPV on linux to consume the media.
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 40
+favouriteCount: 118
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699372560 {#1617
date: 2023-11-07 16:56:00.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#1626 …}
+votes: Doctrine\ORM\PersistentCollection {#2383 …}
+reports: Doctrine\ORM\PersistentCollection {#1883 …}
+favourites: Doctrine\ORM\PersistentCollection {#1906 …}
+notifications: Doctrine\ORM\PersistentCollection {#1708 …}
+badges: Doctrine\ORM\PersistentCollection {#2391 …}
+children: [
App\Entity\EntryComment {#1709}
]
-id: 9762
-titleTs: "'begin':3 'center':8 'media':7 'set':4"
-bodyTs: "'16tb':3 '2600':17 'absolut':39 'access':29 'android':69 'cabinet':14 'card':21 'consum':75 'consumpt':60 'dedic':5 'devic':35 'go':52 'graphic':20 'instal':24 'linux':73 'machin':61 'media':59,77 'mpv':71 'nas':4 'noob':40 'openmediavault':25 'p':62 'pleas':46 'ryzen':16 'server':45 'set':42 'show':9 'smb':32 'store':7 'tell':47 'turn':55 'tv':8 'use':66 'usual':65 'via':31 'vlc':67"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699190737
+visibility: "visible "
+apId: "https://lemm.ee/post/13813898"
+editedAt: null
+createdAt: DateTimeImmutable @1699104337 {#1630
date: 2023-11-04 14:25:37.0 +01:00
}
+__isInitialized__: true
…2
}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: null
+root: null
+body: """
For sailing the high seas/acquiring more Linux ISOs, get a torrent-client, qbitorent is probably the most popular (and depending on where you are a vpn-subscription), then set it up with the arrs:\n
\n
[wiki.servarr.com](https://wiki.servarr.com/)
"""
+lang: "en"
+isAdult: false
+favouriteCount: 4
+score: 0
+lastActive: DateTime @1699130393 {#1435
date: 2023-11-04 21:39:53.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@agame@lemm.ee"
]
+children: Doctrine\ORM\PersistentCollection {#1572 …}
+nested: Doctrine\ORM\PersistentCollection {#1581 …}
+votes: Doctrine\ORM\PersistentCollection {#1579 …}
+reports: Doctrine\ORM\PersistentCollection {#1577 …}
+favourites: Doctrine\ORM\PersistentCollection {#1573 …}
+notifications: Doctrine\ORM\PersistentCollection {#1650 …}
-id: 90772
-bodyTs: "'/)':40 'arr':36 'client':13 'depend':21 'get':9 'high':4 'iso':8 'linux':7 'popular':19 'probabl':16 'qbitor':14 'sail':2 'seas/acquiring':5 'set':31 'subscript':29 'torrent':12 'torrent-cli':11 'vpn':28 'vpn-subscript':27 'wiki.servarr.com':37,39 'wiki.servarr.com/)':38"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563757"
+editedAt: null
+createdAt: DateTimeImmutable @1699130393 {#1438
date: 2023-11-04 21:39:53.0 +01:00
}
+"title": 90772
} |
|
Show voter details
|
| 7 |
DENIED
|
edit
|
App\Entity\EntryComment {#1709
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1582
+user: Proxies\__CG__\App\Entity\User {#1620 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "How-to-begin-setting-up-a-media-center"
+title: "How to begin setting up a media center?"
+url: null
+body: """
I have 16TB NAS dedicated to storing TV shows. It is just a cabinet with ryzen 2600 and no graphics card. I have installed openmediavault in it to access it via smb to other devices. I am an absolute noob in setting up a server. Please tell me how I should go on about turning it into a media consumption machine.\n
\n
P. S: I usually use VLC on android and MPV on linux to consume the media.
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 40
+favouriteCount: 118
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699372560 {#1617
date: 2023-11-07 16:56:00.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#1626 …}
+votes: Doctrine\ORM\PersistentCollection {#2383 …}
+reports: Doctrine\ORM\PersistentCollection {#1883 …}
+favourites: Doctrine\ORM\PersistentCollection {#1906 …}
+notifications: Doctrine\ORM\PersistentCollection {#1708 …}
+badges: Doctrine\ORM\PersistentCollection {#2391 …}
+children: [
App\Entity\EntryComment {#1709}
]
-id: 9762
-titleTs: "'begin':3 'center':8 'media':7 'set':4"
-bodyTs: "'16tb':3 '2600':17 'absolut':39 'access':29 'android':69 'cabinet':14 'card':21 'consum':75 'consumpt':60 'dedic':5 'devic':35 'go':52 'graphic':20 'instal':24 'linux':73 'machin':61 'media':59,77 'mpv':71 'nas':4 'noob':40 'openmediavault':25 'p':62 'pleas':46 'ryzen':16 'server':45 'set':42 'show':9 'smb':32 'store':7 'tell':47 'turn':55 'tv':8 'use':66 'usual':65 'via':31 'vlc':67"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699190737
+visibility: "visible "
+apId: "https://lemm.ee/post/13813898"
+editedAt: null
+createdAt: DateTimeImmutable @1699104337 {#1630
date: 2023-11-04 14:25:37.0 +01:00
}
+__isInitialized__: true
…2
}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: null
+root: null
+body: """
For sailing the high seas/acquiring more Linux ISOs, get a torrent-client, qbitorent is probably the most popular (and depending on where you are a vpn-subscription), then set it up with the arrs:\n
\n
[wiki.servarr.com](https://wiki.servarr.com/)
"""
+lang: "en"
+isAdult: false
+favouriteCount: 4
+score: 0
+lastActive: DateTime @1699130393 {#1435
date: 2023-11-04 21:39:53.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@agame@lemm.ee"
]
+children: Doctrine\ORM\PersistentCollection {#1572 …}
+nested: Doctrine\ORM\PersistentCollection {#1581 …}
+votes: Doctrine\ORM\PersistentCollection {#1579 …}
+reports: Doctrine\ORM\PersistentCollection {#1577 …}
+favourites: Doctrine\ORM\PersistentCollection {#1573 …}
+notifications: Doctrine\ORM\PersistentCollection {#1650 …}
-id: 90772
-bodyTs: "'/)':40 'arr':36 'client':13 'depend':21 'get':9 'high':4 'iso':8 'linux':7 'popular':19 'probabl':16 'qbitor':14 'sail':2 'seas/acquiring':5 'set':31 'subscript':29 'torrent':12 'torrent-cli':11 'vpn':28 'vpn-subscript':27 'wiki.servarr.com':37,39 'wiki.servarr.com/)':38"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563757"
+editedAt: null
+createdAt: DateTimeImmutable @1699130393 {#1438
date: 2023-11-04 21:39:53.0 +01:00
}
+"title": 90772
} |
|
Show voter details
|
| 8 |
DENIED
|
moderate
|
App\Entity\EntryComment {#1709
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1582
+user: Proxies\__CG__\App\Entity\User {#1620 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "How-to-begin-setting-up-a-media-center"
+title: "How to begin setting up a media center?"
+url: null
+body: """
I have 16TB NAS dedicated to storing TV shows. It is just a cabinet with ryzen 2600 and no graphics card. I have installed openmediavault in it to access it via smb to other devices. I am an absolute noob in setting up a server. Please tell me how I should go on about turning it into a media consumption machine.\n
\n
P. S: I usually use VLC on android and MPV on linux to consume the media.
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 40
+favouriteCount: 118
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699372560 {#1617
date: 2023-11-07 16:56:00.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#1626 …}
+votes: Doctrine\ORM\PersistentCollection {#2383 …}
+reports: Doctrine\ORM\PersistentCollection {#1883 …}
+favourites: Doctrine\ORM\PersistentCollection {#1906 …}
+notifications: Doctrine\ORM\PersistentCollection {#1708 …}
+badges: Doctrine\ORM\PersistentCollection {#2391 …}
+children: [
App\Entity\EntryComment {#1709}
]
-id: 9762
-titleTs: "'begin':3 'center':8 'media':7 'set':4"
-bodyTs: "'16tb':3 '2600':17 'absolut':39 'access':29 'android':69 'cabinet':14 'card':21 'consum':75 'consumpt':60 'dedic':5 'devic':35 'go':52 'graphic':20 'instal':24 'linux':73 'machin':61 'media':59,77 'mpv':71 'nas':4 'noob':40 'openmediavault':25 'p':62 'pleas':46 'ryzen':16 'server':45 'set':42 'show':9 'smb':32 'store':7 'tell':47 'turn':55 'tv':8 'use':66 'usual':65 'via':31 'vlc':67"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699190737
+visibility: "visible "
+apId: "https://lemm.ee/post/13813898"
+editedAt: null
+createdAt: DateTimeImmutable @1699104337 {#1630
date: 2023-11-04 14:25:37.0 +01:00
}
+__isInitialized__: true
…2
}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: null
+root: null
+body: """
For sailing the high seas/acquiring more Linux ISOs, get a torrent-client, qbitorent is probably the most popular (and depending on where you are a vpn-subscription), then set it up with the arrs:\n
\n
[wiki.servarr.com](https://wiki.servarr.com/)
"""
+lang: "en"
+isAdult: false
+favouriteCount: 4
+score: 0
+lastActive: DateTime @1699130393 {#1435
date: 2023-11-04 21:39:53.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@agame@lemm.ee"
]
+children: Doctrine\ORM\PersistentCollection {#1572 …}
+nested: Doctrine\ORM\PersistentCollection {#1581 …}
+votes: Doctrine\ORM\PersistentCollection {#1579 …}
+reports: Doctrine\ORM\PersistentCollection {#1577 …}
+favourites: Doctrine\ORM\PersistentCollection {#1573 …}
+notifications: Doctrine\ORM\PersistentCollection {#1650 …}
-id: 90772
-bodyTs: "'/)':40 'arr':36 'client':13 'depend':21 'get':9 'high':4 'iso':8 'linux':7 'popular':19 'probabl':16 'qbitor':14 'sail':2 'seas/acquiring':5 'set':31 'subscript':29 'torrent':12 'torrent-cli':11 'vpn':28 'vpn-subscript':27 'wiki.servarr.com':37,39 'wiki.servarr.com/)':38"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563757"
+editedAt: null
+createdAt: DateTimeImmutable @1699130393 {#1438
date: 2023-11-04 21:39:53.0 +01:00
}
+"title": 90772
} |
|
Show voter details
|
| 9 |
DENIED
|
ROLE_USER
|
null |
|
Show voter details
|
| 10 |
DENIED
|
moderate
|
Proxies\__CG__\App\Entity\Entry {#1528
+user: Proxies\__CG__\App\Entity\User {#2382 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "Can-t-figure-out-how-to-download-an-embedded-PDF"
+title: "Can't figure out how to download an embedded PDF"
+url: null
+body: """
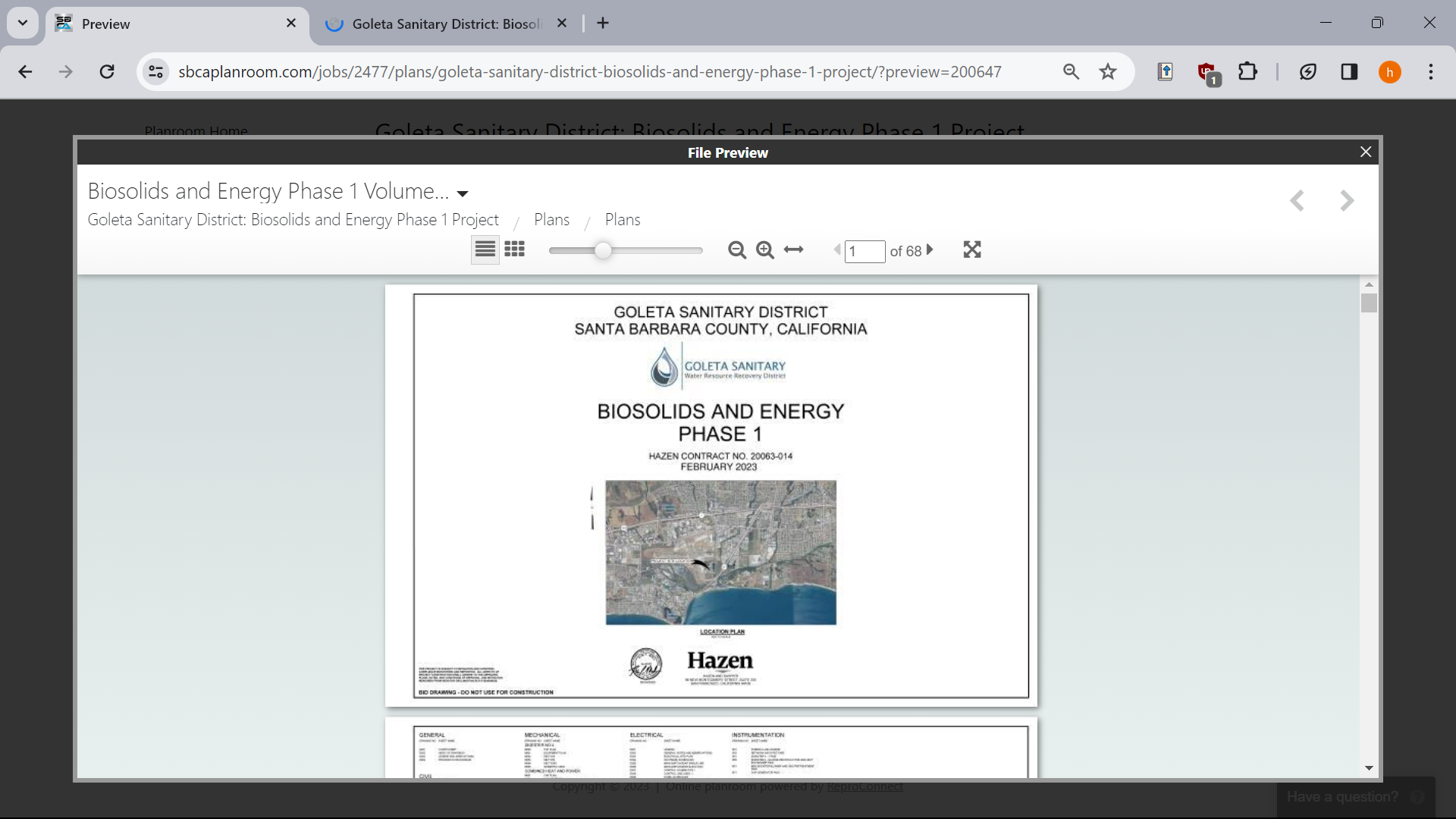
Ok so I want to download this embedded PDF/document in order to physically print it. The website allows me to view it as much as I want, but is asking me to fork over 25 + tax USD so i can download the document.\n
\n
\n
\n
Obviously, i don’t want to do that, so I try to download the embedded document via inspect element. But, the weird thing is it not actually loading a pdf, but like really small pictures of each page:\n
\n
\n
\n
So, my question is basically how can I download this document in order to print it?\n
\n
PdF link: [sbcaplanroom.com/…/goleta-sanitary-district-bioso…](https://www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 31
+favouriteCount: 70
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699131221 {#1596
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#2456 …}
+votes: Doctrine\ORM\PersistentCollection {#2453 …}
+reports: Doctrine\ORM\PersistentCollection {#2454 …}
+favourites: Doctrine\ORM\PersistentCollection {#1737 …}
+notifications: Doctrine\ORM\PersistentCollection {#1735 …}
+badges: Doctrine\ORM\PersistentCollection {#1618 …}
+children: [
App\Entity\EntryComment {#1561
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1528 …2}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+root: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+body: "Just as a tiny nitpick: PDFs *can* be just a collection of images. If there’s text I would hope that they’re embedded as text or vectors, which is what would usually happen if you export a document from a program (that isn’t completely bs). So texts / vector graphics etc should not be images usually (unless you *scan* a document as a PDF - which I hate with a passion but can see that people prefer a single PDF over a collection of image files). Even then you could OCR the imges / PDF to make it searchable etc. Anyway in this case it seems to be a collection of images indeed ^__^"
+lang: "en"
+isAdult: false
+favouriteCount: 1
+score: 0
+lastActive: DateTime @1699131221 {#1670
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@nooneescapesthelaw@lemmy.ml"
"@princessnorah@lemmy.blahaj.zone"
]
+children: Doctrine\ORM\PersistentCollection {#1711 …}
+nested: Doctrine\ORM\PersistentCollection {#1692 …}
+votes: Doctrine\ORM\PersistentCollection {#1686 …}
+reports: Doctrine\ORM\PersistentCollection {#1680 …}
+favourites: Doctrine\ORM\PersistentCollection {#1683 …}
+notifications: Doctrine\ORM\PersistentCollection {#1702 …}
-id: 90809
-bodyTs: "'anyway':100 'bs':47 'case':103 'collect':11,83,109 'complet':46 'could':90 'document':39,62 'embed':24 'etc':52,99 'even':87 'export':37 'file':86 'graphic':51 'happen':34 'hate':68 'hope':20 'imag':13,56,85,111 'img':93 'inde':112 'isn':44 'make':96 'nitpick':5 'ocr':91 'passion':71 'pdf':65,80,94 'pdfs':6 'peopl':76 'prefer':77 'program':42 're':23 'scan':60 'searchabl':98 'see':74 'seem':105 'singl':79 'text':17,26,49 'tini':4 'unless':58 'usual':33,57 'vector':28,50 'would':19,32"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563866"
+editedAt: null
+createdAt: DateTimeImmutable @1699131221 {#1527
date: 2023-11-04 21:53:41.0 +01:00
}
+"title": 90809
}
]
-id: 9494
-titleTs: "'download':7 'embed':9 'figur':3 'pdf':10"
-bodyTs: "'/goleta-sanitary-district-bioso':107 '/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':110 '/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':87 '/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':46 '25':35 'actual':73 'allow':18 'ask':30 'basic':92 'document':43,62,98 'download':6,41,59,96 'element':65 'embed':8,61 'fork':33 'inspect':64 'lemmy.ml':45,86 'lemmy.ml/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':85 'lemmy.ml/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':44 'like':78 'link':105 'load':74 'much':24 'obvious':47 'ok':1 'order':11,100 'page':84 'pdf':76,104 'pdf/document':9 'physic':13 'pictur':81 'print':14,102 'question':90 'realli':79 'sbcaplanroom.com':106 'small':80 'tax':36 'thing':69 'tri':57 'usd':37 'via':63 'view':21 'want':4,27,51 'websit':17 'weird':68 'www.sbcaplanroom.com':109 'www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':108"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699153528
+visibility: "visible "
+apId: "https://lemmy.ml/post/7465894"
+editedAt: DateTimeImmutable @1699074835 {#1566
date: 2023-11-04 06:13:55.0 +01:00
}
+createdAt: DateTimeImmutable @1699067128 {#1554
date: 2023-11-04 04:05:28.0 +01:00
}
+__isInitialized__: true
…2
} |
|
Show voter details
|
| 11 |
DENIED
|
edit
|
Proxies\__CG__\App\Entity\Entry {#1528
+user: Proxies\__CG__\App\Entity\User {#2382 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "Can-t-figure-out-how-to-download-an-embedded-PDF"
+title: "Can't figure out how to download an embedded PDF"
+url: null
+body: """
Ok so I want to download this embedded PDF/document in order to physically print it. The website allows me to view it as much as I want, but is asking me to fork over 25 + tax USD so i can download the document.\n
\n
\n
\n
Obviously, i don’t want to do that, so I try to download the embedded document via inspect element. But, the weird thing is it not actually loading a pdf, but like really small pictures of each page:\n
\n
\n
\n
So, my question is basically how can I download this document in order to print it?\n
\n
PdF link: [sbcaplanroom.com/…/goleta-sanitary-district-bioso…](https://www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 31
+favouriteCount: 70
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699131221 {#1596
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#2456 …}
+votes: Doctrine\ORM\PersistentCollection {#2453 …}
+reports: Doctrine\ORM\PersistentCollection {#2454 …}
+favourites: Doctrine\ORM\PersistentCollection {#1737 …}
+notifications: Doctrine\ORM\PersistentCollection {#1735 …}
+badges: Doctrine\ORM\PersistentCollection {#1618 …}
+children: [
App\Entity\EntryComment {#1561
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1528 …2}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+root: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+body: "Just as a tiny nitpick: PDFs *can* be just a collection of images. If there’s text I would hope that they’re embedded as text or vectors, which is what would usually happen if you export a document from a program (that isn’t completely bs). So texts / vector graphics etc should not be images usually (unless you *scan* a document as a PDF - which I hate with a passion but can see that people prefer a single PDF over a collection of image files). Even then you could OCR the imges / PDF to make it searchable etc. Anyway in this case it seems to be a collection of images indeed ^__^"
+lang: "en"
+isAdult: false
+favouriteCount: 1
+score: 0
+lastActive: DateTime @1699131221 {#1670
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@nooneescapesthelaw@lemmy.ml"
"@princessnorah@lemmy.blahaj.zone"
]
+children: Doctrine\ORM\PersistentCollection {#1711 …}
+nested: Doctrine\ORM\PersistentCollection {#1692 …}
+votes: Doctrine\ORM\PersistentCollection {#1686 …}
+reports: Doctrine\ORM\PersistentCollection {#1680 …}
+favourites: Doctrine\ORM\PersistentCollection {#1683 …}
+notifications: Doctrine\ORM\PersistentCollection {#1702 …}
-id: 90809
-bodyTs: "'anyway':100 'bs':47 'case':103 'collect':11,83,109 'complet':46 'could':90 'document':39,62 'embed':24 'etc':52,99 'even':87 'export':37 'file':86 'graphic':51 'happen':34 'hate':68 'hope':20 'imag':13,56,85,111 'img':93 'inde':112 'isn':44 'make':96 'nitpick':5 'ocr':91 'passion':71 'pdf':65,80,94 'pdfs':6 'peopl':76 'prefer':77 'program':42 're':23 'scan':60 'searchabl':98 'see':74 'seem':105 'singl':79 'text':17,26,49 'tini':4 'unless':58 'usual':33,57 'vector':28,50 'would':19,32"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563866"
+editedAt: null
+createdAt: DateTimeImmutable @1699131221 {#1527
date: 2023-11-04 21:53:41.0 +01:00
}
+"title": 90809
}
]
-id: 9494
-titleTs: "'download':7 'embed':9 'figur':3 'pdf':10"
-bodyTs: "'/goleta-sanitary-district-bioso':107 '/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':110 '/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':87 '/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':46 '25':35 'actual':73 'allow':18 'ask':30 'basic':92 'document':43,62,98 'download':6,41,59,96 'element':65 'embed':8,61 'fork':33 'inspect':64 'lemmy.ml':45,86 'lemmy.ml/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':85 'lemmy.ml/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':44 'like':78 'link':105 'load':74 'much':24 'obvious':47 'ok':1 'order':11,100 'page':84 'pdf':76,104 'pdf/document':9 'physic':13 'pictur':81 'print':14,102 'question':90 'realli':79 'sbcaplanroom.com':106 'small':80 'tax':36 'thing':69 'tri':57 'usd':37 'via':63 'view':21 'want':4,27,51 'websit':17 'weird':68 'www.sbcaplanroom.com':109 'www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':108"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699153528
+visibility: "visible "
+apId: "https://lemmy.ml/post/7465894"
+editedAt: DateTimeImmutable @1699074835 {#1566
date: 2023-11-04 06:13:55.0 +01:00
}
+createdAt: DateTimeImmutable @1699067128 {#1554
date: 2023-11-04 04:05:28.0 +01:00
}
+__isInitialized__: true
…2
} |
|
Show voter details
|
| 12 |
DENIED
|
moderate
|
Proxies\__CG__\App\Entity\Entry {#1528
+user: Proxies\__CG__\App\Entity\User {#2382 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "Can-t-figure-out-how-to-download-an-embedded-PDF"
+title: "Can't figure out how to download an embedded PDF"
+url: null
+body: """
Ok so I want to download this embedded PDF/document in order to physically print it. The website allows me to view it as much as I want, but is asking me to fork over 25 + tax USD so i can download the document.\n
\n
\n
\n
Obviously, i don’t want to do that, so I try to download the embedded document via inspect element. But, the weird thing is it not actually loading a pdf, but like really small pictures of each page:\n
\n
\n
\n
So, my question is basically how can I download this document in order to print it?\n
\n
PdF link: [sbcaplanroom.com/…/goleta-sanitary-district-bioso…](https://www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 31
+favouriteCount: 70
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699131221 {#1596
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#2456 …}
+votes: Doctrine\ORM\PersistentCollection {#2453 …}
+reports: Doctrine\ORM\PersistentCollection {#2454 …}
+favourites: Doctrine\ORM\PersistentCollection {#1737 …}
+notifications: Doctrine\ORM\PersistentCollection {#1735 …}
+badges: Doctrine\ORM\PersistentCollection {#1618 …}
+children: [
App\Entity\EntryComment {#1561
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1528 …2}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+root: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+body: "Just as a tiny nitpick: PDFs *can* be just a collection of images. If there’s text I would hope that they’re embedded as text or vectors, which is what would usually happen if you export a document from a program (that isn’t completely bs). So texts / vector graphics etc should not be images usually (unless you *scan* a document as a PDF - which I hate with a passion but can see that people prefer a single PDF over a collection of image files). Even then you could OCR the imges / PDF to make it searchable etc. Anyway in this case it seems to be a collection of images indeed ^__^"
+lang: "en"
+isAdult: false
+favouriteCount: 1
+score: 0
+lastActive: DateTime @1699131221 {#1670
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@nooneescapesthelaw@lemmy.ml"
"@princessnorah@lemmy.blahaj.zone"
]
+children: Doctrine\ORM\PersistentCollection {#1711 …}
+nested: Doctrine\ORM\PersistentCollection {#1692 …}
+votes: Doctrine\ORM\PersistentCollection {#1686 …}
+reports: Doctrine\ORM\PersistentCollection {#1680 …}
+favourites: Doctrine\ORM\PersistentCollection {#1683 …}
+notifications: Doctrine\ORM\PersistentCollection {#1702 …}
-id: 90809
-bodyTs: "'anyway':100 'bs':47 'case':103 'collect':11,83,109 'complet':46 'could':90 'document':39,62 'embed':24 'etc':52,99 'even':87 'export':37 'file':86 'graphic':51 'happen':34 'hate':68 'hope':20 'imag':13,56,85,111 'img':93 'inde':112 'isn':44 'make':96 'nitpick':5 'ocr':91 'passion':71 'pdf':65,80,94 'pdfs':6 'peopl':76 'prefer':77 'program':42 're':23 'scan':60 'searchabl':98 'see':74 'seem':105 'singl':79 'text':17,26,49 'tini':4 'unless':58 'usual':33,57 'vector':28,50 'would':19,32"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563866"
+editedAt: null
+createdAt: DateTimeImmutable @1699131221 {#1527
date: 2023-11-04 21:53:41.0 +01:00
}
+"title": 90809
}
]
-id: 9494
-titleTs: "'download':7 'embed':9 'figur':3 'pdf':10"
-bodyTs: "'/goleta-sanitary-district-bioso':107 '/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':110 '/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':87 '/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':46 '25':35 'actual':73 'allow':18 'ask':30 'basic':92 'document':43,62,98 'download':6,41,59,96 'element':65 'embed':8,61 'fork':33 'inspect':64 'lemmy.ml':45,86 'lemmy.ml/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':85 'lemmy.ml/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':44 'like':78 'link':105 'load':74 'much':24 'obvious':47 'ok':1 'order':11,100 'page':84 'pdf':76,104 'pdf/document':9 'physic':13 'pictur':81 'print':14,102 'question':90 'realli':79 'sbcaplanroom.com':106 'small':80 'tax':36 'thing':69 'tri':57 'usd':37 'via':63 'view':21 'want':4,27,51 'websit':17 'weird':68 'www.sbcaplanroom.com':109 'www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':108"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699153528
+visibility: "visible "
+apId: "https://lemmy.ml/post/7465894"
+editedAt: DateTimeImmutable @1699074835 {#1566
date: 2023-11-04 06:13:55.0 +01:00
}
+createdAt: DateTimeImmutable @1699067128 {#1554
date: 2023-11-04 04:05:28.0 +01:00
}
+__isInitialized__: true
…2
} |
|
Show voter details
|
| 13 |
DENIED
|
ROLE_USER
|
null |
|
Show voter details
|
| 14 |
DENIED
|
moderate
|
App\Entity\EntryComment {#1561
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1528
+user: Proxies\__CG__\App\Entity\User {#2382 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "Can-t-figure-out-how-to-download-an-embedded-PDF"
+title: "Can't figure out how to download an embedded PDF"
+url: null
+body: """
Ok so I want to download this embedded PDF/document in order to physically print it. The website allows me to view it as much as I want, but is asking me to fork over 25 + tax USD so i can download the document.\n
\n
\n
\n
Obviously, i don’t want to do that, so I try to download the embedded document via inspect element. But, the weird thing is it not actually loading a pdf, but like really small pictures of each page:\n
\n
\n
\n
So, my question is basically how can I download this document in order to print it?\n
\n
PdF link: [sbcaplanroom.com/…/goleta-sanitary-district-bioso…](https://www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 31
+favouriteCount: 70
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699131221 {#1596
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#2456 …}
+votes: Doctrine\ORM\PersistentCollection {#2453 …}
+reports: Doctrine\ORM\PersistentCollection {#2454 …}
+favourites: Doctrine\ORM\PersistentCollection {#1737 …}
+notifications: Doctrine\ORM\PersistentCollection {#1735 …}
+badges: Doctrine\ORM\PersistentCollection {#1618 …}
+children: [
App\Entity\EntryComment {#1561}
]
-id: 9494
-titleTs: "'download':7 'embed':9 'figur':3 'pdf':10"
-bodyTs: "'/goleta-sanitary-district-bioso':107 '/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':110 '/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':87 '/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':46 '25':35 'actual':73 'allow':18 'ask':30 'basic':92 'document':43,62,98 'download':6,41,59,96 'element':65 'embed':8,61 'fork':33 'inspect':64 'lemmy.ml':45,86 'lemmy.ml/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':85 'lemmy.ml/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':44 'like':78 'link':105 'load':74 'much':24 'obvious':47 'ok':1 'order':11,100 'page':84 'pdf':76,104 'pdf/document':9 'physic':13 'pictur':81 'print':14,102 'question':90 'realli':79 'sbcaplanroom.com':106 'small':80 'tax':36 'thing':69 'tri':57 'usd':37 'via':63 'view':21 'want':4,27,51 'websit':17 'weird':68 'www.sbcaplanroom.com':109 'www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':108"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699153528
+visibility: "visible "
+apId: "https://lemmy.ml/post/7465894"
+editedAt: DateTimeImmutable @1699074835 {#1566
date: 2023-11-04 06:13:55.0 +01:00
}
+createdAt: DateTimeImmutable @1699067128 {#1554
date: 2023-11-04 04:05:28.0 +01:00
}
+__isInitialized__: true
…2
}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+root: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+body: "Just as a tiny nitpick: PDFs *can* be just a collection of images. If there’s text I would hope that they’re embedded as text or vectors, which is what would usually happen if you export a document from a program (that isn’t completely bs). So texts / vector graphics etc should not be images usually (unless you *scan* a document as a PDF - which I hate with a passion but can see that people prefer a single PDF over a collection of image files). Even then you could OCR the imges / PDF to make it searchable etc. Anyway in this case it seems to be a collection of images indeed ^__^"
+lang: "en"
+isAdult: false
+favouriteCount: 1
+score: 0
+lastActive: DateTime @1699131221 {#1670
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@nooneescapesthelaw@lemmy.ml"
"@princessnorah@lemmy.blahaj.zone"
]
+children: Doctrine\ORM\PersistentCollection {#1711 …}
+nested: Doctrine\ORM\PersistentCollection {#1692 …}
+votes: Doctrine\ORM\PersistentCollection {#1686 …}
+reports: Doctrine\ORM\PersistentCollection {#1680 …}
+favourites: Doctrine\ORM\PersistentCollection {#1683 …}
+notifications: Doctrine\ORM\PersistentCollection {#1702 …}
-id: 90809
-bodyTs: "'anyway':100 'bs':47 'case':103 'collect':11,83,109 'complet':46 'could':90 'document':39,62 'embed':24 'etc':52,99 'even':87 'export':37 'file':86 'graphic':51 'happen':34 'hate':68 'hope':20 'imag':13,56,85,111 'img':93 'inde':112 'isn':44 'make':96 'nitpick':5 'ocr':91 'passion':71 'pdf':65,80,94 'pdfs':6 'peopl':76 'prefer':77 'program':42 're':23 'scan':60 'searchabl':98 'see':74 'seem':105 'singl':79 'text':17,26,49 'tini':4 'unless':58 'usual':33,57 'vector':28,50 'would':19,32"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563866"
+editedAt: null
+createdAt: DateTimeImmutable @1699131221 {#1527
date: 2023-11-04 21:53:41.0 +01:00
}
+"title": 90809
} |
|
Show voter details
|
| 15 |
DENIED
|
edit
|
App\Entity\EntryComment {#1561
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1528
+user: Proxies\__CG__\App\Entity\User {#2382 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "Can-t-figure-out-how-to-download-an-embedded-PDF"
+title: "Can't figure out how to download an embedded PDF"
+url: null
+body: """
Ok so I want to download this embedded PDF/document in order to physically print it. The website allows me to view it as much as I want, but is asking me to fork over 25 + tax USD so i can download the document.\n
\n
\n
\n
Obviously, i don’t want to do that, so I try to download the embedded document via inspect element. But, the weird thing is it not actually loading a pdf, but like really small pictures of each page:\n
\n
\n
\n
So, my question is basically how can I download this document in order to print it?\n
\n
PdF link: [sbcaplanroom.com/…/goleta-sanitary-district-bioso…](https://www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 31
+favouriteCount: 70
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699131221 {#1596
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#2456 …}
+votes: Doctrine\ORM\PersistentCollection {#2453 …}
+reports: Doctrine\ORM\PersistentCollection {#2454 …}
+favourites: Doctrine\ORM\PersistentCollection {#1737 …}
+notifications: Doctrine\ORM\PersistentCollection {#1735 …}
+badges: Doctrine\ORM\PersistentCollection {#1618 …}
+children: [
App\Entity\EntryComment {#1561}
]
-id: 9494
-titleTs: "'download':7 'embed':9 'figur':3 'pdf':10"
-bodyTs: "'/goleta-sanitary-district-bioso':107 '/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':110 '/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':87 '/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':46 '25':35 'actual':73 'allow':18 'ask':30 'basic':92 'document':43,62,98 'download':6,41,59,96 'element':65 'embed':8,61 'fork':33 'inspect':64 'lemmy.ml':45,86 'lemmy.ml/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':85 'lemmy.ml/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':44 'like':78 'link':105 'load':74 'much':24 'obvious':47 'ok':1 'order':11,100 'page':84 'pdf':76,104 'pdf/document':9 'physic':13 'pictur':81 'print':14,102 'question':90 'realli':79 'sbcaplanroom.com':106 'small':80 'tax':36 'thing':69 'tri':57 'usd':37 'via':63 'view':21 'want':4,27,51 'websit':17 'weird':68 'www.sbcaplanroom.com':109 'www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':108"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699153528
+visibility: "visible "
+apId: "https://lemmy.ml/post/7465894"
+editedAt: DateTimeImmutable @1699074835 {#1566
date: 2023-11-04 06:13:55.0 +01:00
}
+createdAt: DateTimeImmutable @1699067128 {#1554
date: 2023-11-04 04:05:28.0 +01:00
}
+__isInitialized__: true
…2
}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+root: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+body: "Just as a tiny nitpick: PDFs *can* be just a collection of images. If there’s text I would hope that they’re embedded as text or vectors, which is what would usually happen if you export a document from a program (that isn’t completely bs). So texts / vector graphics etc should not be images usually (unless you *scan* a document as a PDF - which I hate with a passion but can see that people prefer a single PDF over a collection of image files). Even then you could OCR the imges / PDF to make it searchable etc. Anyway in this case it seems to be a collection of images indeed ^__^"
+lang: "en"
+isAdult: false
+favouriteCount: 1
+score: 0
+lastActive: DateTime @1699131221 {#1670
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@nooneescapesthelaw@lemmy.ml"
"@princessnorah@lemmy.blahaj.zone"
]
+children: Doctrine\ORM\PersistentCollection {#1711 …}
+nested: Doctrine\ORM\PersistentCollection {#1692 …}
+votes: Doctrine\ORM\PersistentCollection {#1686 …}
+reports: Doctrine\ORM\PersistentCollection {#1680 …}
+favourites: Doctrine\ORM\PersistentCollection {#1683 …}
+notifications: Doctrine\ORM\PersistentCollection {#1702 …}
-id: 90809
-bodyTs: "'anyway':100 'bs':47 'case':103 'collect':11,83,109 'complet':46 'could':90 'document':39,62 'embed':24 'etc':52,99 'even':87 'export':37 'file':86 'graphic':51 'happen':34 'hate':68 'hope':20 'imag':13,56,85,111 'img':93 'inde':112 'isn':44 'make':96 'nitpick':5 'ocr':91 'passion':71 'pdf':65,80,94 'pdfs':6 'peopl':76 'prefer':77 'program':42 're':23 'scan':60 'searchabl':98 'see':74 'seem':105 'singl':79 'text':17,26,49 'tini':4 'unless':58 'usual':33,57 'vector':28,50 'would':19,32"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563866"
+editedAt: null
+createdAt: DateTimeImmutable @1699131221 {#1527
date: 2023-11-04 21:53:41.0 +01:00
}
+"title": 90809
} |
|
Show voter details
|
| 16 |
DENIED
|
moderate
|
App\Entity\EntryComment {#1561
+user: App\Entity\User {#264 …}
+entry: Proxies\__CG__\App\Entity\Entry {#1528
+user: Proxies\__CG__\App\Entity\User {#2382 …}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+domain: Proxies\__CG__\App\Entity\Domain {#2461 …}
+slug: "Can-t-figure-out-how-to-download-an-embedded-PDF"
+title: "Can't figure out how to download an embedded PDF"
+url: null
+body: """
Ok so I want to download this embedded PDF/document in order to physically print it. The website allows me to view it as much as I want, but is asking me to fork over 25 + tax USD so i can download the document.\n
\n
\n
\n
Obviously, i don’t want to do that, so I try to download the embedded document via inspect element. But, the weird thing is it not actually loading a pdf, but like really small pictures of each page:\n
\n
\n
\n
So, my question is basically how can I download this document in order to print it?\n
\n
PdF link: [sbcaplanroom.com/…/goleta-sanitary-district-bioso…](https://www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)
"""
+type: "article"
+lang: "en"
+isOc: false
+hasEmbed: false
+commentCount: 31
+favouriteCount: 70
+score: 0
+isAdult: false
+sticky: false
+lastActive: DateTime @1699131221 {#1596
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+adaAmount: 0
+tags: null
+mentions: null
+comments: Doctrine\ORM\PersistentCollection {#2456 …}
+votes: Doctrine\ORM\PersistentCollection {#2453 …}
+reports: Doctrine\ORM\PersistentCollection {#2454 …}
+favourites: Doctrine\ORM\PersistentCollection {#1737 …}
+notifications: Doctrine\ORM\PersistentCollection {#1735 …}
+badges: Doctrine\ORM\PersistentCollection {#1618 …}
+children: [
App\Entity\EntryComment {#1561}
]
-id: 9494
-titleTs: "'download':7 'embed':9 'figur':3 'pdf':10"
-bodyTs: "'/goleta-sanitary-district-bioso':107 '/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':110 '/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':87 '/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':46 '25':35 'actual':73 'allow':18 'ask':30 'basic':92 'document':43,62,98 'download':6,41,59,96 'element':65 'embed':8,61 'fork':33 'inspect':64 'lemmy.ml':45,86 'lemmy.ml/pictrs/image/b89d74d2-559a-4ef2-9fd6-9114d83a8d4d.png)':85 'lemmy.ml/pictrs/image/bbed0e20-73ab-49b2-a943-4e436124b836.png)':44 'like':78 'link':105 'load':74 'much':24 'obvious':47 'ok':1 'order':11,100 'page':84 'pdf':76,104 'pdf/document':9 'physic':13 'pictur':81 'print':14,102 'question':90 'realli':79 'sbcaplanroom.com':106 'small':80 'tax':36 'thing':69 'tri':57 'usd':37 'via':63 'view':21 'want':4,27,51 'websit':17 'weird':68 'www.sbcaplanroom.com':109 'www.sbcaplanroom.com/jobs/2477/plans/goleta-sanitary-district-biosolids-and-energy-phase-1-project/?preview=200647)':108"
+cross: false
+upVotes: 0
+downVotes: 0
+ranking: 1699153528
+visibility: "visible "
+apId: "https://lemmy.ml/post/7465894"
+editedAt: DateTimeImmutable @1699074835 {#1566
date: 2023-11-04 06:13:55.0 +01:00
}
+createdAt: DateTimeImmutable @1699067128 {#1554
date: 2023-11-04 04:05:28.0 +01:00
}
+__isInitialized__: true
…2
}
+magazine: Proxies\__CG__\App\Entity\Magazine {#1574 …}
+image: null
+parent: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+root: Proxies\__CG__\App\Entity\EntryComment {#1616 …}
+body: "Just as a tiny nitpick: PDFs *can* be just a collection of images. If there’s text I would hope that they’re embedded as text or vectors, which is what would usually happen if you export a document from a program (that isn’t completely bs). So texts / vector graphics etc should not be images usually (unless you *scan* a document as a PDF - which I hate with a passion but can see that people prefer a single PDF over a collection of image files). Even then you could OCR the imges / PDF to make it searchable etc. Anyway in this case it seems to be a collection of images indeed ^__^"
+lang: "en"
+isAdult: false
+favouriteCount: 1
+score: 0
+lastActive: DateTime @1699131221 {#1670
date: 2023-11-04 21:53:41.0 +01:00
}
+ip: null
+tags: null
+mentions: [
"@nooneescapesthelaw@lemmy.ml"
"@princessnorah@lemmy.blahaj.zone"
]
+children: Doctrine\ORM\PersistentCollection {#1711 …}
+nested: Doctrine\ORM\PersistentCollection {#1692 …}
+votes: Doctrine\ORM\PersistentCollection {#1686 …}
+reports: Doctrine\ORM\PersistentCollection {#1680 …}
+favourites: Doctrine\ORM\PersistentCollection {#1683 …}
+notifications: Doctrine\ORM\PersistentCollection {#1702 …}
-id: 90809
-bodyTs: "'anyway':100 'bs':47 'case':103 'collect':11,83,109 'complet':46 'could':90 'document':39,62 'embed':24 'etc':52,99 'even':87 'export':37 'file':86 'graphic':51 'happen':34 'hate':68 'hope':20 'imag':13,56,85,111 'img':93 'inde':112 'isn':44 'make':96 'nitpick':5 'ocr':91 'passion':71 'pdf':65,80,94 'pdfs':6 'peopl':76 'prefer':77 'program':42 're':23 'scan':60 'searchabl':98 'see':74 'seem':105 'singl':79 'text':17,26,49 'tini':4 'unless':58 'usual':33,57 'vector':28,50 'would':19,32"
+ranking: 0
+commentCount: 0
+upVotes: 0
+downVotes: 0
+visibility: "visible "
+apId: "https://beehaw.org/comment/1563866"
+editedAt: null
+createdAt: DateTimeImmutable @1699131221 {#1527
date: 2023-11-04 21:53:41.0 +01:00
}
+"title": 90809
} |
|
Show voter details
|
| 17 |
DENIED
|
ROLE_ADMIN
|
null |
|
Show voter details
|
| 18 |
DENIED
|
ROLE_MODERATOR
|
null |
|
Show voter details
|